Proxy vs Reverse Proxy
What is the difference between a Proxy and a Reverse Proxy?
A web proxy accepts http requests from a client (typically a browser), forwards those requests to a webserver, then returns the response to the browser. Simple right?
So, a reverse proxy must just do the reverse? Accept requests from a webserver, issues those requests to a browser, then return the response? WRONG. Just writing that makes me cringe.
But I’ll confess, that’s what I thought the first time I heard the term reverse proxy.
The light finally went on for me over at Stack Overflow.
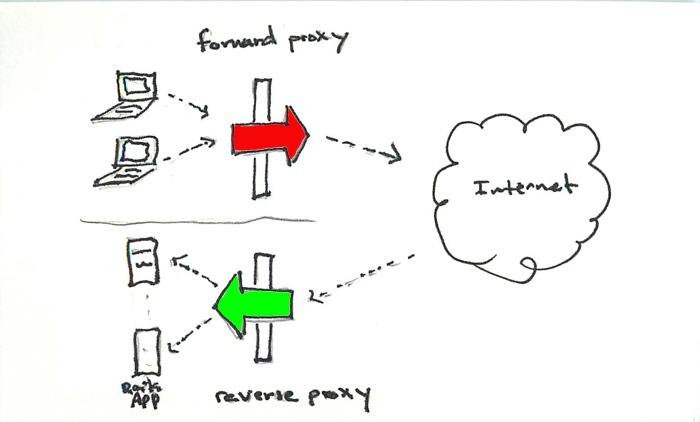
Proxies (sometimes called Forward Proxies) and Reverse Proxies are fundamentally the same: both accept requests, forward those request to another server and return the response. The differences:
Forward Proxies
- live on the same network as the client computer.
- handle outgoing request traffic
- requires client (browser) configuration
- are commonly used in workplace settings to cache frequently accessed website content and to block access to inappropriate sites.
Reverse Proxies
- usually live on the same network as the website’s servers (CDN’s are an exception).
- handle incoming request traffic
- the client is typically unaware that its traffic is passing through a reverse proxy.
- are comonly used by websites to cache static content (images, css, etc), to load balance and to forward requests to app servers.
I still don’t understand why its called a reverse proxy. What exactly is reversed?
The direction of the network traffic is reversed.
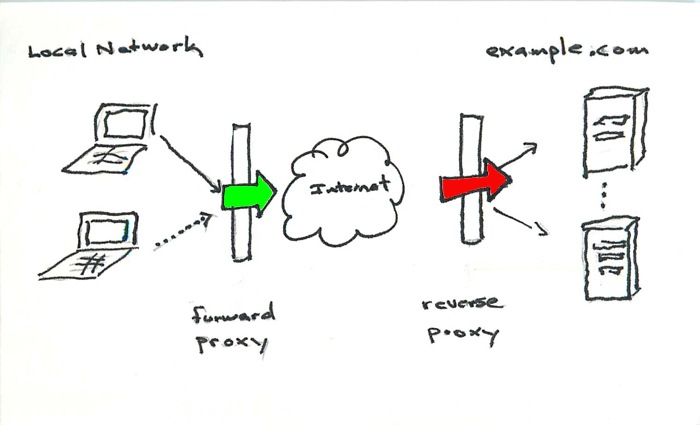
It helps to think from the perspective of a network admin managing one network.
Imagine you’ve got two proxies setup on your corporate network. One proxy caches content whenever users visit sites on the internet. The other proxy sits in front of your corporate website load balancing requests across several Ruby on Rails app servers. That caching proxy is handling OUTBOUND traffic, requests going from the local network out to the internet.
That load balancer is handling INBOUND traffic, requests coming from the internet into the local network.